Making your site fast is not hard. I know I should tell you the opposite, selling you my services for fixing your site or teaching you my skills, but that is not what I believe in. All the knowledge and tools you need are all out there on the wonderful web, open source and ready for you to make use of. You don’t need my help.
Making your site fast to users (who else would we be making it fast for?) means making it seem fast, which means looking at metrics like the time to first render and the Speed Index.
Forget about the weight of your page for a while. Forget about gzipping content. Forget about concatenating scripts, about setting correct cache-headers, about creating image sprites and about using SVG. None of these things matter much for the time to first render, and more importantly — they do not stand in your way for making your site fast. Don’t get paralyzed by all the thing you could do. Do one thing. Make your site fast.
Another thing that doesn’t matter for making your site fast: JS frameworks. It was most recently in the wake of the launch of Facebook’s Instant Articles that we somehow got debating again whether we can have a fast web when we use JS frameworks. I’m not quite sure how the proponents for the we-must-drop-frameworks-to-become-fast came to their conclusion. Perhaps they weren’t talking about speed but about accessibility. Perhaps they relied on older performance concepts that we used to rely on to measure speed (such as Total Page Load Time).
No matter how they got there, they got it wrong. As your JS should never be on the critical path for rendering, it is completely irrelevant for your time to first render, and hence your site’s speed. In terms of making your site fast, the only thing you need from a JS framework is an ability to render on the server (Which if your framework doesn’t have by now — ditch it).
The steps to greatly improving your site’s actual speed:
Make sure you’ve got proper content in your HTML, returned by your server.
Move your all your <script> tags out of the head of your html, and put them just before your closing body tag. If you don’t need to support IE9 or older browsers, you can instead keep the scripts in the head and just add a async tag them.
Move all your stylesheet (link) tags out of the head of your html, and put them just before your closing body tag. Or use loadCSS.
Inline critical path css for each page early in the head. If your css is really small, like for this site, you can inline your full css. Otherwise, use a tool like Penthouse, or a service like Criticalcss.com. Full disclosure: I’m behind both of those.
There are a lot of misconceptions about what it takes to improve the speed of a website, and of the Web as a whole. It’s time to get rid of old concepts that no longer serves us, and focus on what we know matters. We can improve the time to render for our sites, and it will make all the difference for our users.
All the things that I said didn’t matter for time to first render are still things you should do to improve your website performance. Revisit these things after you’ve sorted your time to first render.
Isomorphic JS is becoming increasingly popular, and for good reasons. Users gets a better experience: the application or website loads and renders faster, doesn’t stop working completely when JS fails (and it will), and provides an accessible and crawl-able baseline (real DOM markup returned from the server), free for the client to progressively enhance.
So why doesn’t everyone run their apps isomorphically? Well, it is extra work to setup, and there’s the fear that isomorphism will lead to unmanageable levels of complexity in the code. There are also frameworks out there that still just don’t jibe at all with server rendering (looking at you, Angular). Even using something like React that is perfectly suited for Isomorphism, there still a lack of tutorials and documentation for how to achieve an isomorphic setup.
In this post I will walk through the isomorphic React setup we use for the new version of State.com, and the problems we encountered along the way.
Before we go into the Isomorphic flow, let’s cover a standard React client render flow first:
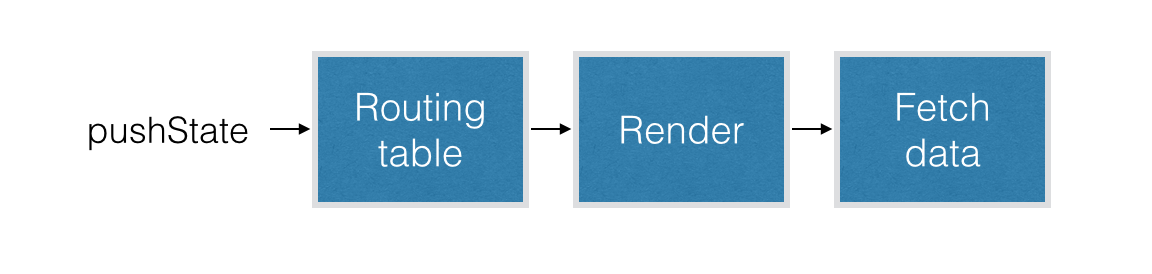
Client side React render flow
The render flow is triggered by a new URL, in most cases set by your router via history.pushState. The URL matches a route, which maps to a <Page> component which you then render using React.render. If the <Page> needs some new data, it is requested from the React component’s componentDidMount lifecycle method. Note: We talk about Pages in our application; React and others refer to Views.
When rendering React isomorphically the overall flow is very similar, but the thing that changes is data fetching.
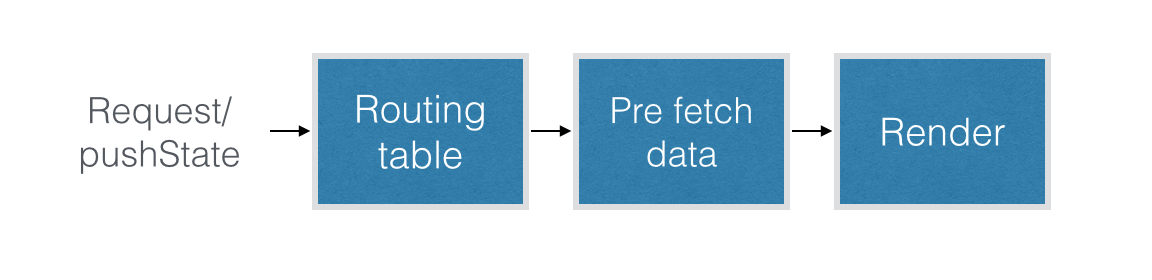
Isomorphic React render flow
Note that we use an isomorphic router with the same routing table on client and server to avoid code duplication. The server render uses React.renderToString instead of React.render, and it also embeds the React output into a full HTML response.
On the server we cannot request data in componentDidMount as we would on the client, as it is never called by React.renderToString (even if it was; asynchronous data requests wouldn’t be serialisable). So what do we do instead? We fetch the data before rendering React.
When we started building the next version of State.com using Isomorphic React we initially declared the data requests needed for our <Page>s in our routing table. We found that this bloated the code in the routing table, and that it was confusing having the data logic for our app split into multiple places: some in the routing table, some still in our React components. In the end we went back to declaring these data request inside the components.
How can we declare the data requests inside components, but access this information before we render? The statics component property that React offers allows us to do just that. It’s a property on your components where you can declare methods that can be access outside of React.
Inside we add a requestsForProps on our <Page> components. The method returns request information based on which we can later make requests — we’re not making the requests in this method itself.
Note that the userProvider is part of an abstraction layer for our api that allows us to declare those data requests using the same syntax for both server and client.
We can now call MyPage.requestForProps to access those requests before we render. We execute the requests, and then on the server we wait for them all to return before we render React, whereas on the client we render immediately and let React re-render as response data comes back. Note: This gives us a single point in the code which encapsulates all requests we need to make, making it a focal point for combining/optimising those requests. Another note on the requestsForProps name: other people seem to use names such as fetchData for this functionality. We think such a name is misleading for us, given that the method doesn’t fetch the data itself, and that the final decision on what to fetch is made upstream.
Now we have an isomorphic render flow allowing us to use the same code to render both on the server and the client, but we’re not done just yet. After we’ve rendered on the server, we need to do a special “boot” render of React on the client in order to hook up event listeners. This “boot” render is different from every other client render in that we should reuse the render context that we used on the server, rather than deriving it in the usual way (via requestForProps etc). We also need to use the same context because if we pass different props to React then React’s virtual DOM will diff, and React will be forced to re-render the DOM (React will give you a checksum warning for this).
What is needed is a mechanism for passing the server render context to the client. We achieve this by just dumping all that info into a JSON inside a script tag when rendering on the server, that we then parse on the client:
// server
<script id=‘context’ type=‘application/json’>
var context = JSON.stringify({
page: Page.displayName,
data: data
...
});
</script>
// client
var context = JSON.parse(
document.getElementById(‘context’).textContent
);
Note that we cannot put the <Page> component itself in this context JSON, as it is a function and therefor cannot be serialised. We rely on it’s displayName instead — if you do too, make sure it’s unique, and set on all your Page components!
Also note that you might have to do some escaping of the content you put into the context, f.e. of literal < and > characters.
With this context available, you’ll now be able to render on the client with exactly the same props and data as on the server. If you have a very simple data model for your application or website, this might be all you need for your isomorphic setup. If the model is complicated however, or if you cache your data, or it changes over time, then perhaps you should be using Flux — so let’s talk about setting that up isomorphically. Should I use Flux?
Note that with Relay on the horizon, the way we use Flux will probably change significantly over the next few months. Below I describe our current implementation of a Flux pattern.
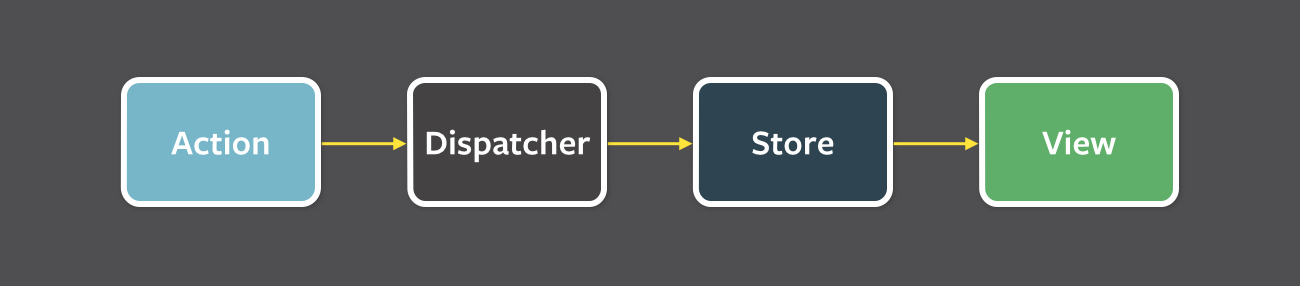
I’m not going to cover Flux in any depth here; if you don’t know anything at all about it you’ll probably be better off if you go and read up on it before continuing here. What’s important to understand is that it is a unidirectional data flow pattern and that <Page> components (Views in the diagram below) get their data from Stores.
Flux Unidirectional data flow
Early on we were confused about using Flux isomorphically — how could you run Stores on the server? Should you? We started out trying the opposite, running Flux and Stores only on the client, but in the end we found that it required more code and complexity compared to our isomorphic implementation. In the end, running Stores on the server wasn’t very complicated, there are just a few things you need to be aware of, so let’s go through them now.
Flux Stores are singletons, meaning that you start them when the app starts, and then just let them live on. For the server this has the consequence that you need to take care to not leak user specific data between requests. If user B comes visiting your site after user A, and the server is still running Stores with user A’s data.. the data will leak into user B’s session. To prevent that, we need to be able to reset Stores, which fortunately is quite trivial:
On the server we need to call this method on each store after we’re done with our render. We also use this method on the client; for example when a user logs out and then in as a different user.
Another difference for the server environment is that the whole Flux data flow (from populating Stores with data until we reset them again) needs to be synchronous, because we cannot allow multiple requests to modify the same Stores at the same time. By keeping these execution steps synchronous we prevent subsequent requests from interfering with the currently handled request. On the client we don’t have this kind of requirement.
In practice this means that if you use Actions on the server, they need to be synchronous, if you use a Dispatcher, the same goes for it. I presume you could instead make your server render logic wait for an async Dispatcher to signal that it’s ready before moving on. We never tried this approach.
After we’ve got our data into our stores on the server, we don’t want to have to re-enact the same data flow on the client “boot” render, so now the render context object we talked about before needs to contain bootstrapped Stores instead of raw request data. Bootstrapping Stores is as trivial as resetting them: all that’s needed is functions on each Store to snapshot and restore its data.
After we’ve synchronously populated our Stores with the data fetched via requestForProps, we can add their snapshots into the context object that we’re passing from server to the client (replacing the raw data we had there before):
// server
<script id=‘context’ type=‘application/json’>
var context = JSON.stringify({
...
snapshots: {
"UserStore": UserStore.snapshot(),
...
}
});
</script>
The client just does the reverse; calls restore on each Store in context.snapshot, with its data. This needs to happen beforeReact.render is called.
If you’ve have managed to follow along what I’ve covered so far you should (hopefully) have a really good understanding of how to set up an Isomorphic render flow with data Stores for React.
I’m going to conclude this post with a section on how we populate our Flux Stores. This pattern is not required for Isomorphic React, but it has worked very well for us as an isomorphic data store distribution solution.
The first step we go through is normalising our nested api responses, which makes the data easier to use with Flux Stores. If your api already gives back normalised data, you can skip this step.
Basically what we want to achieve is having one Store per resource type in our api (f.e. User) being responsible for storing that type of data. Any other resource type that appears nested in the objects in a Store will just be held as ID’s. As an example, the UserStore contains full User objects, but Users appearing inside the Statements in the StatementStore will only be kept as id’s.
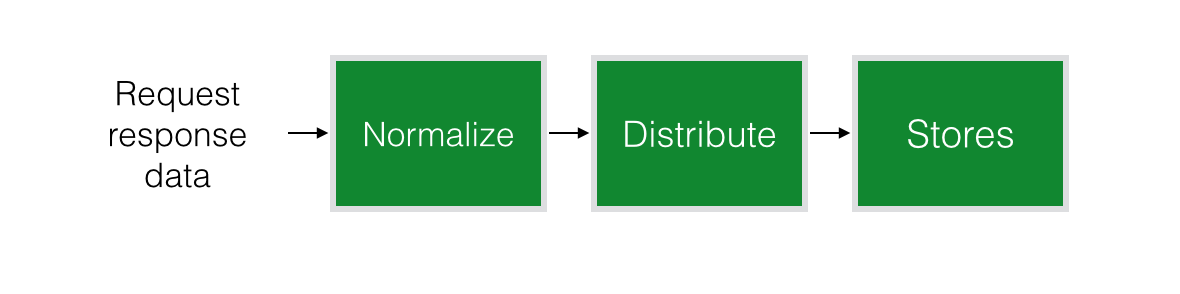
We use normalizr for our api response normalisation, which splits any JSON data into one object per resource type, populated with all the identified objects of that type found in the response, and with all nested resource objects replaced by their id’s.
With the data already organised in exactly the way each Store wants it, distributing it is easy. We trigger one Action per resource type in the normalised array, with the corresponding data, and each Store listens to these events for the resource type it’s storing.
Going back to the render flow I have introduced in this post, I hope it’s easy to see why this distribution pattern works well for us. When making the requests given by requestForProps, the data automatically flows into the Stores! All we need to do is to ensure the Stores are running before we make the requests. The exact same pattern is used during runtime on the client.
Use Statics to co-locate data requests with component logic
Bootstrap server render context
Snapshot, restore and reset Stores
Optional: Auto distribute request data to stores
You can run your React application isomorphically, even if you have have complicated data models and use Flux and multiple Stores. It won’t have to lead to extra complexity. All code we write when adding a new Store, Route, API endpoint or Component is isomorphic, and defined once. The extra code that is needed, such as the abstraction layer on top of our api, and the different render sequence, is code that only has to be invested in once, and that isn’t large or complicated either.
I’ve shared this information thinking it should be helpful to people in the same situation as we in my company were in a few months back. If you find anything in the post unclear, or if you just want more information — don’t hesitate to ask me.
Building menu’s for responsive websites can be tricky. For small devices, we basically want to hide the menu by default, so that it doesn’t take up a lot of space, and then show it only when the user want’s it. For an overview of solutions for this, check this article on CSS tricks. The problem is that most methods either require javascript, or have weird, hacky, unsemantical HTML, or both. Personally, I never even considered any solution relying on javascript – the idea of some users being completely incapable of accessing something as crucial as the navigation just seems to wrong to me. Some variations of the javascript solutions just leaves the menu expanded for non-javascript users – which is better – but then the menu blocks most of the users screen instead, forcing the user to scroll past it to get to the content. Of course we can do better.
The :target solution
When I first read about the :target solution, I was sold – no javascript required and semantic markup. Perfect. I have been using this method, or variations of it ever since. It’s used on this website (in the format described below). If you aren’t familiar witih this method, go check out this tutorial. It’s basically toggling showing the menu via modyfying the hash part of the url, so leading the user to #nav would show the menu.
A drawback
Unfortunately this method pollutes the browser history — every time the user opens or closes the menu, a new entry is placed in their browser history. This can make it really annoying to try to get back to a previous page, if you have to click through a lot of ‘pages’ where you were just interacting with the menu. Clearly, menu interaction does not belong in the browser history. But that’s very easy to fix, with javascript!
But you said javascript solutions were not okay?
This is where progressive enhancement comes in. While it’s not okay to require javascript in order to provide something as fundamental as a menu, it’s absolutely okay to improve an already functional experience using javascript. In fact, that’s what you should do. Using javascript, we just intercept and block the clicks on our menu triggering anchor links, and instead we toggle some css class for activating the menu.
var $nav = $(".mobile-menu");
$(".mobile-menu-show-button").on("click", function(e){
e.preventDefault() //prevents #nav from registering in browser
$nav.addClass("active"); //shows the menu
});
//add the .active trigger to show the menu
#nav.active .nav-list,
#nav:target .nav-list //what we're STILL using for non-js
{
//show menu...
}
In the end, we get the best of both worlds — a fully functional, semantical, non-javascript dependent mobile menu experience for our non javascript users, and not only that but also a clean browser history for our javascript users.
If you have any questions or comments, please let me know!
Importing SVG with filters causes rasterization problems in Adobe Illustrator
Posted on September 30, 2013
Just a quick note of a bug I found today at work:
When importing SVG’s into Adobe Illustrator, if the SVG has filters this will cause the SVG to be (permanently) rasterized: inside AI, on export (to f.e. PDF), and in print. Normally SVG filters are only rasterized in the preview image inside AI, and will still look sharp on export and in print.
Workaround
You can get your SVG to work just fine in Illustrator if you just follow these simple steps:
Open your SVG in Illustrator
Create a new AI document
Copy your SVG from the open .svg document into your new .ai document
Manually import or copy over the SVG filters that you originally had in the SVG into your .ai file.
The 4th step is what makes this workaround slightly annoying, but it’s not too bad. Just open up your original SVG in any text editor, copy your first SVG filter (including the <filter> tags with the ID) and then go into AI, fire upp the Appearance panel, select the element that had the filter applied to it, click on the name of the filter, and click to edit it. It should open up a list of SVG filters to choose from. Click ‘Add New’, and then finally paste in the filter you copied from your svg file. Do the same for all your filters (cross your fingers you didn’t have too many!), and voila, it all works!
Sometimes Illustrator seems a bit fidgety with displaying changes you make to your SVG filters. Close the SVG filters panel, re-open it again, make sure ‘preview changes’ is selected. Then select another SVG filter, wait for the preview to refresh, then change back to the one you want. This should solve the problem!
I posted on the Adobe help forums here, to see what the Community has to say about this. As I prefer to work with Adobe Fireworks, or directly in the browser, Illustrator is not my area of expertise. If you know any better workaround, please send me a tweet!
If you are on a desktop, or even a new smartphone (iPhone 5 or similar), you probably can’t see any difference between the sliders. But the majority of mobile users have less powerful devices than you do! Also keep in mind that this is basically a blank page with minimal code bound to the sliding event. The heavier the page, the greater the improvement when using the CSS Transforms. This is why I think this technique should be used for all sliders.
So what’s the difference between the sliders? One line of code.
The first slider uses good old absolute positioning for moving the slider handle around:
The second slider does exactly the same thing, but uses CSS Transforms for the positioning.
$("#slider-2").on("slide",function(e){
/*..same as before..*/
/*apply position using CSS Transforms!*/
$(this).css("transform", "translate3d("+newPos+", 0, 0)");
/*(remember vendor prefixes!)*/
});
If you are using any kind of library like jQuery or jQuery mobile, you might find yourself unable to modify the slider javascript. Rather than doing that, you can semi-enhance the slider just using CSS.
The third slider only applies one initial CSS Transform to the slider handle to force hardware accelerations (despite still using absolute positioning in the slider javascript):
When building HTML5 apps and websites to compete with native apps for mobile users, one thing stands out as lacking on the web: performance. Part of it is slow page load and rendering times, but it also comes down to non responsive UI elements and transitions. You just can’t create a slick experience when your sliders (,page scrolling, slideshows, pickers widgets etc.) perform badly. Fortunately we have these tricks we can use to improve the performance!
I get really disappointed when I see that even the big players, like jQuery UI and even jQuery Mobile still don’t get this right. In fact, I searched high and low until I could find even one library that do use CSS Transforms for their sliders: Sencha Touch. Good on you guys.
For everyone else — it’s time to pick up the slack. Let’s fix our sliders for our mobile users.